Today, the path of a software-as-a-service company seems both obvious and paradoxical. Expanding customer acquisition creates operational inertia, but this growth simultaneously highlights architectural weaknesses which can derail growth. For companies scaling from $5 million to $100 million ARR, the infrastructure that supports their product becomes as important as the product itself. Cloud-native, scalable SaaS architectures will dictate whether a company can take advantage of market opportunity or implode under its own weight. The pace of this change should outstrip the user demand for it; a necessity that has leaders reevaluating everything from the way systems are designed to how they are deployed and maintained.

As we get more customers, this puts a distance between functional code and production ready infrastructure. Feature that works for 10000 users breaks down at 100000 + users. Where something works reasonably well in one geography, it breaks when it comes to serving the global markets. This is a reality that high-growth companies face earlier and more acutely compared to their slower-growing peers. And the answer cannot be reactive patching. It demands systematic architectural approach — anticipating load patterns, complexity in data and operational challenges before they occur.
Why Scalable SaaS Architecture Is a Strategic Priority
The software markets have reached the end of the exploratory phase. Regardless of company size, customers expect enterprise-grade performance from every vendor. The expectation mentality has changed and technical architecture is no longer back office — it is a competitive differentiator! We´ve seen how organizations that wait to modernize their infrastructure, cannot close enterprise deals, cannot globalize, and cannot ship enterprise-grade features without bringing their systems down.
The economics support this view. McKinsey research on cloud adoption shows that companies investing in modern infrastructure early capture market share more effectively than those postponing these decisions.
Last but not the least, the move towards distributed systems and cloud-native is a reaction, some might say even necessity in practicality. High-growth scenarios cannot be sustained by monolithic applications because they can neither handle the concurrency, nor data volume or feature complexity required. The question for technical leaders is no longer if they should modernize, but how soon they can do so without impacting business as usual.
Regulatory pressures compound these challenges. Architecturally, compliance frameworks such as SOC 2, GDPR, and HIPAA will enforce which databases you can use, your access controls, the residency of your data, etc. Meeting this challenge at scale requires purposeful design decisions and an embedding of them from the onset, rather than a retrofitting.
The Structural Pressures of High-Growth SaaS
Expanding User Base and Data Volumes
User growth creates immediate technical pressure across multiple system layers. Each new customer adds transactional load, storage requirements, and query complexity. The relationship is not linear. Doubling the user base often triples database operations as customers generate more interconnected data over time. Peak usage patterns amplify this effect. When customers cluster their activity during business hours in specific time zones, infrastructure must handle surge capacity that far exceeds average load.
Latency becomes the primary concern. Response times that users tolerate during low-traffic periods become unacceptable when concurrent requests multiply. Database queries that execute in milliseconds against small datasets slow to seconds when tables grow beyond certain thresholds. Network round-trips that are invisible in single-region deployments become noticeable when serving users across continents. These performance degradations happen gradually, then suddenly, often catching engineering teams unprepared.
Concurrency adds another dimension. Systems designed for sequential processing break when thousands of users attempt simultaneous operations. Lock contention in databases, race conditions in application logic, and resource exhaustion in compute layers all emerge as user activity intensifies. The technical debt accumulated during early development phases surfaces precisely when the company can least afford disruption.
Increasing Complexity of Product Workflows
Feature velocity creates architectural entropy. Each new capability introduces dependencies, integrations, and state management requirements that increase system complexity. What begins as a clean service boundary becomes tangled as features interact in unexpected ways. Product teams push for rapid iteration, creating tension between architectural discipline and market responsiveness.
The compounding effect is real. A feature that seems isolated during design often requires data from multiple domains, triggering changes across service boundaries. Authentication becomes authorization becomes audit logging becomes compliance reporting. Simple workflows expand into multi-stage processes involving queues, background jobs, and eventual consistency patterns. Technical teams find themselves managing not just code but the intricate coordination between dozens of semi-independent components.
This complexity tax shows up in deployment cycles, debugging sessions, and incident response. Changes that should take hours require days of coordination. Bugs that should be obvious become detective work across service logs. Outages that should affect one feature cascade through dependent systems. Without intentional architectural boundaries, the system becomes increasingly brittle as it grows.
Reliability and Compliance Expectations
Enterprise customers operate under different assumptions than early adopters. They expect 99.9% uptime, transparent security practices, and contractual liability for data handling. These requirements are not negotiable. Companies that cannot demonstrate mature operational practices lose deals regardless of product superiority.
The mathematical reality of high availability is unforgiving. Three nines of uptime allows less than nine hours of downtime per year. Achieving this requires redundancy at every layer, automated failover, and sophisticated monitoring. Manual intervention introduces too much latency. Human operators cannot respond quickly enough to prevent customer impact during infrastructure failures.
Compliance frameworks impose architectural constraints that affect how data flows through systems. Encrypted data at rest and in transit becomes baseline. Field-level access controls require granular permission models. Audit trails must capture every data modification with tamper-proof logging. These requirements cannot be added as afterthoughts. They must be embedded in the data architecture from the foundation.
Principles of Modern Scalable SaaS Architecture
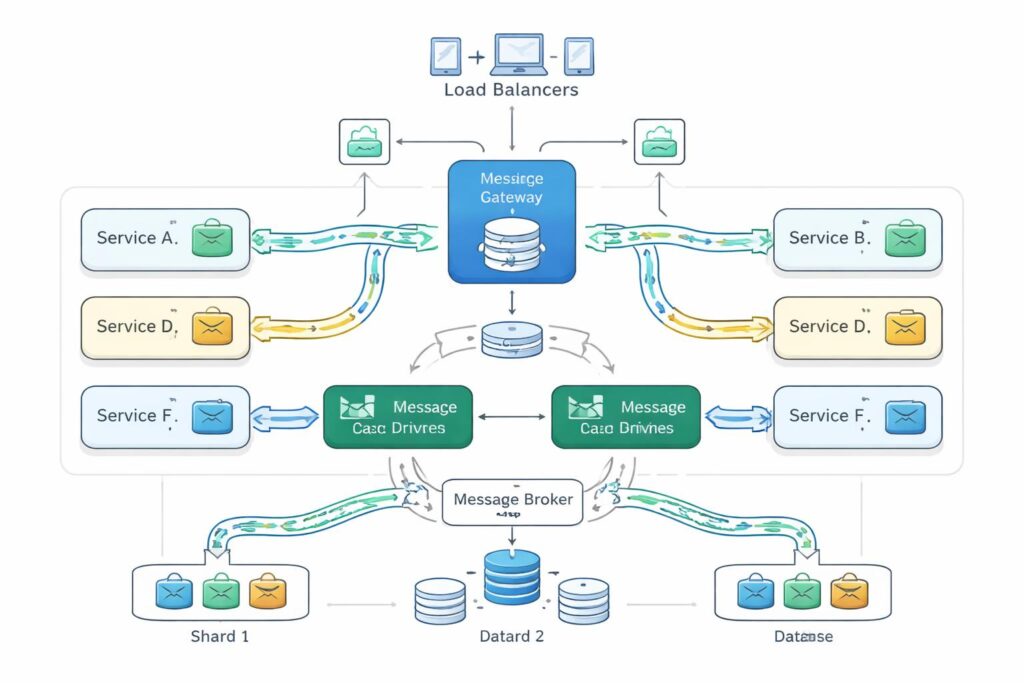
Cloud-Native and Distributed-by-Design
The shift to cloud-native architecture represents more than infrastructure migration. It requires rethinking how applications are structured, deployed, and operated. Microservices decompose monolithic applications into focused components that can be developed, scaled, and maintained independently. Each service owns a specific business domain with clear boundaries and minimal coupling to other services.
Domain isolation provides the foundation for parallel development. Different teams can work on separate services without coordination overhead or merge conflicts. Release cycles decouple, allowing high-velocity teams to deploy frequently while stable services update less often. This organizational benefit matters as much as the technical scalability it enables.
Context boundaries define where one service ends and another begins. Getting these boundaries wrong creates distributed monoliths where services remain tightly coupled despite physical separation. The goal is loose coupling and high cohesion within each domain. Services should communicate through well-defined contracts, not shared databases or tightly synchronized state.
Horizontal Scalability and Stateless Services

Vertical scaling hits physical limits. Adding more CPU and memory to a single server provides diminishing returns and introduces single points of failure. Horizontal scaling distributes load across multiple identical instances, creating linear scalability characteristics. When demand increases, the system adds more instances. When demand drops, excess capacity shuts down.
This approach requires stateless service design. Each request must be self-contained, carrying all necessary information to execute without depending on previous requests or server-side session storage. Authentication becomes token-based. Session data moves to distributed caches. Application servers become disposable, replaceable units that can be added or removed without coordination.
Load balancers distribute incoming requests across available instances using various algorithms. Round-robin provides simple distribution. Least-connections routes to less-busy servers. Weighted routing directs traffic based on instance capacity. The specific algorithm matters less than the architectural principle that any instance can handle any request.
Event-Driven and Asynchronous Processing
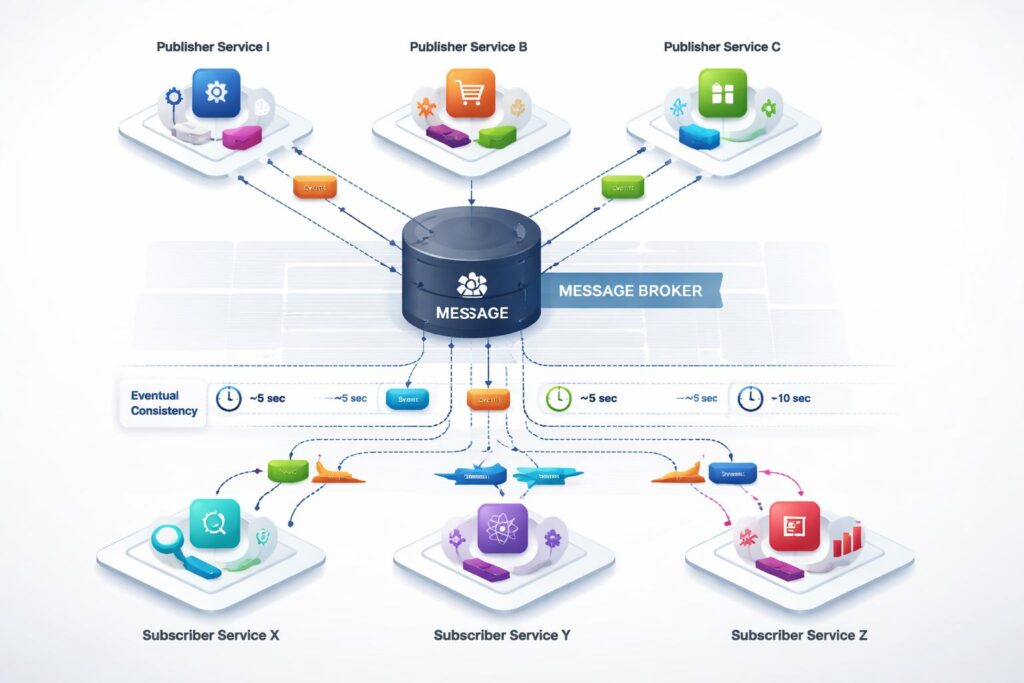
Synchronous request-response patterns create tight coupling between services. When Service A calls Service B, it must wait for a response before continuing. This coupling means that Service A’s performance depends on Service B’s availability and response time. Chains of synchronous calls create cascading failure scenarios where a problem in one service propagates through the entire system.
Event-driven architectures break these dependencies. Services publish events to message brokers when interesting things happen. Other services subscribe to relevant events and react independently. The publisher does not know or care who consumes its events. Subscribers process events at their own pace without blocking the publisher.
This pattern enables eventual consistency, where different parts of the system reach the same state at different times. When a user updates their profile, the change might propagate to analytics systems minutes later. This delay is acceptable because perfect synchronization is neither necessary nor achievable in distributed systems. The trade-off provides resilience and scalability benefits that outweigh the complexity of managing asynchronous workflows.
Multi-Tenancy Models for Growth
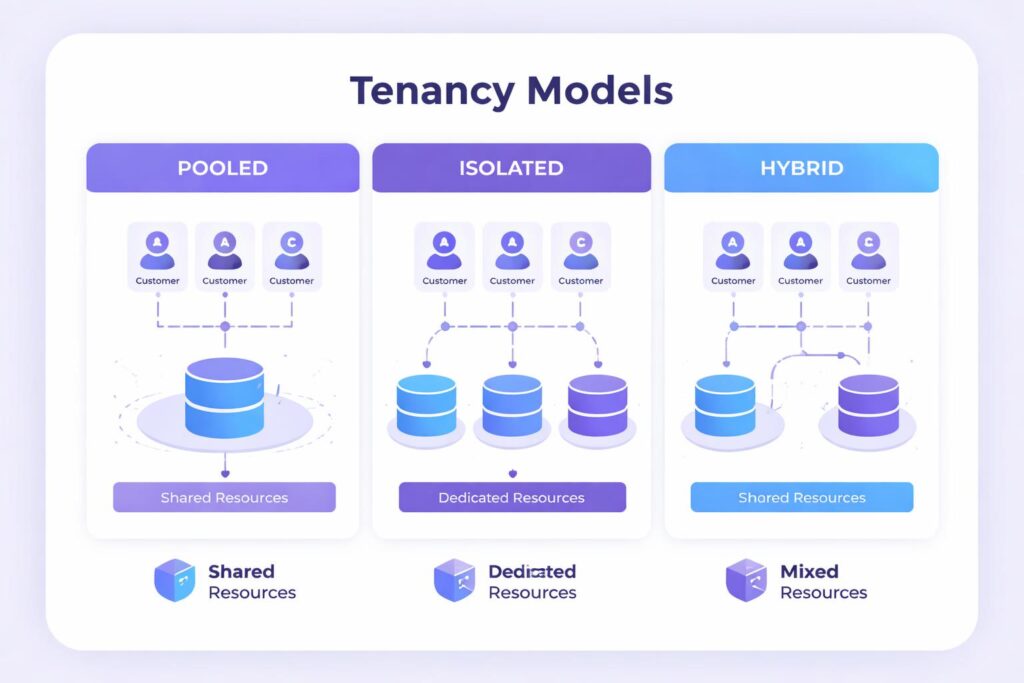
They must isolate customers from each other while delivering predictable performance from shared infrastructure. Tenancy model3: This defines the organization of customer data and compute resources. With pooled tenancy, every customer is placed together in the same database and potentially the same application instances, which is the extreme of shared resources—as such, isolation can be complicated. With isolated tenancy, each customer has their own infrastructure resources, making security management simpler but less efficient.
Hybrid models balance these extremes. Individual small customers share a set of pooled resources, while larger-scale enterprise accounts each receive their own dedicated capacity. This assessment loosely aligns infrastructure costs to customer value at tolerable isolation boundaries. The platform architecture has to enable smooth migrations from one tier of customer to the next.
Identification of the tenant propagates across all layers of the system. Dispatching requests has to send each customer to their dedicated resources. All data queries must use filters on tenant ID to avoid leaking data across customers. It involves tenant-level metrics monitoring, which is crucial for locating resource hogs or unusual patterns. The architectural DNA of this tenant awareness becomes hardwired inside of it.
Core Components of Scalable SaaS Architecture
API Layer and Gateway Architecture
The API gateway serves as the single entry point for all external requests. It handles authentication, request routing, rate limiting, and protocol translation. This centralization simplifies client integration while providing a control point for security policies and traffic management.
Rate limiting protects backend services from excessive load. Each customer receives an allocation based on their subscription tier. Requests exceeding these limits receive throttling responses. This mechanism prevents any single tenant from consuming disproportionate resources or launching accidental denial-of-service attacks through buggy client code.
Request routing directs traffic to appropriate backend services based on URL patterns, headers, or request content. The gateway maintains a routing table that maps external endpoints to internal microservices. This abstraction allows backend restructuring without affecting client applications. Services can be split, merged, or relocated without changing external contracts.
Data Architecture
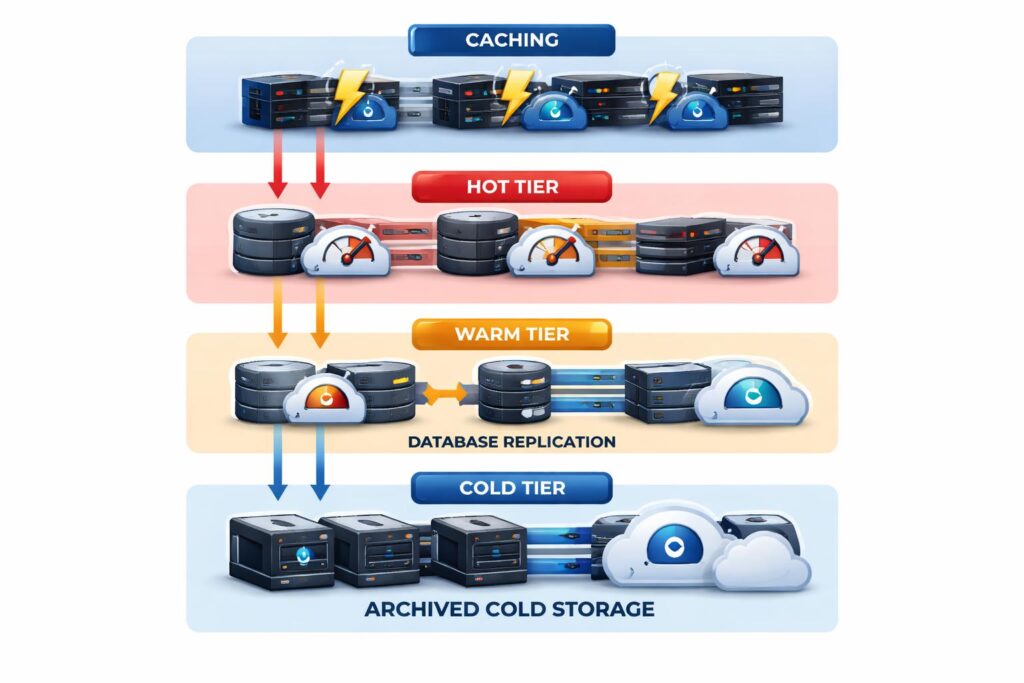
Data strategy determines system scalability more than any other architectural decision. Monolithic databases become bottlenecks as transaction volume grows. The solution involves partitioning data across multiple database instances based on some sharding key. Customer ID works well for multi-tenant applications, ensuring each tenant’s data lands on a consistent shard.
Read replicas offload query traffic from primary databases. Applications route write operations to the primary while distributing reads across replicas. This separation allows read capacity to scale independently from write capacity. For read-heavy workloads, adding replicas provides near-linear scaling without touching the primary database.
Caching layers sit between applications and databases, storing frequently accessed data in memory. Cache hits avoid expensive database queries entirely. The challenge lies in cache invalidation—ensuring cached data remains consistent with the source of truth. Time-based expiration works for data with acceptable staleness. Event-driven invalidation provides stronger consist
ency at the cost of additional complexity.
Storage Strategy
They will have different lifecycle characteristics and access patterns. Newest data needs to be pulled from storage backed by costly SSD. Low-usage historical data has movement to less expensive storage classes. Data that is stored in compliance with regulations and seldom accessed goes to cold storage where data can be retrieved at a slower speed.
Relational versus non-relationalDatabases decision depends on data structure and access patterns. Rel
ational models are suitable for structured data with intricate relationships. Document stores are preferred for flexible schemas and high-velocity writes. Time-series data is one use case that can take advantage of specialized databases for optimized temporal queries. Most larger systems will have multiple types of database with the right tool for the right job.
On the other hand, Object storage is suitable for unstructured data such as files, images, and backu
ps. Cloud providers provide, literally, infinite capacity and extremely high durability promises. Instead of keeping references to objects in the database, applications reference them through URLs. This decoupling enhances the performance of the database and makes content delivery easier by adding the CDN.
Observability and Reliability Layer
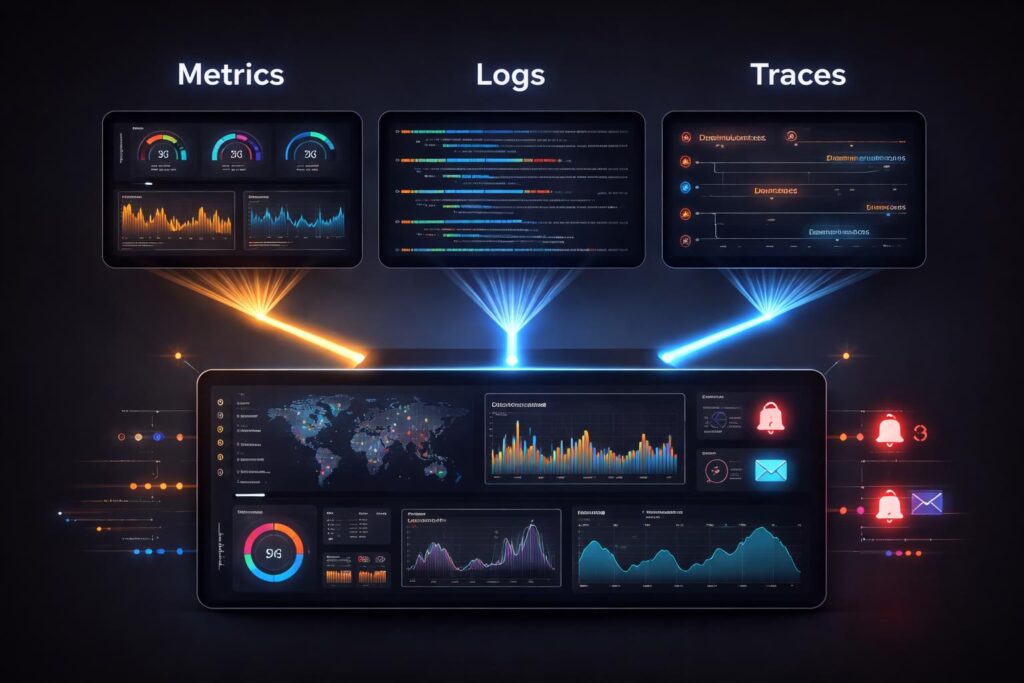
Production systems must expose their internal state through comprehensive instrumentation. Metrics track quantitative measurements like request rates, error percentages, and resource utilization. Logs capture discrete events with contextual information for debugging. Distributed traces follow individual requests across service boundaries, revealing bottlenecks and failures in complex workflows.
These observability pillars work together to provide system visibility. High error rates in metrics trigger investigation through relevant logs. Logs containing transaction IDs connect to distributed traces showing the complete request path. This correlation allows engineers to move quickly from symptom to root cause during incidents.
Service level objectives define reliability targets based on customer impact. A typical SLO might specify that 99.9% of API requests must complete within 500 milliseconds. The system measures actual performance against these objectives and maintains an error budget representing acceptable deviation. When the error budget exhausts, teams pause feature work to focus on reliability improvements.
Enabling Scalability Through Automation and AI
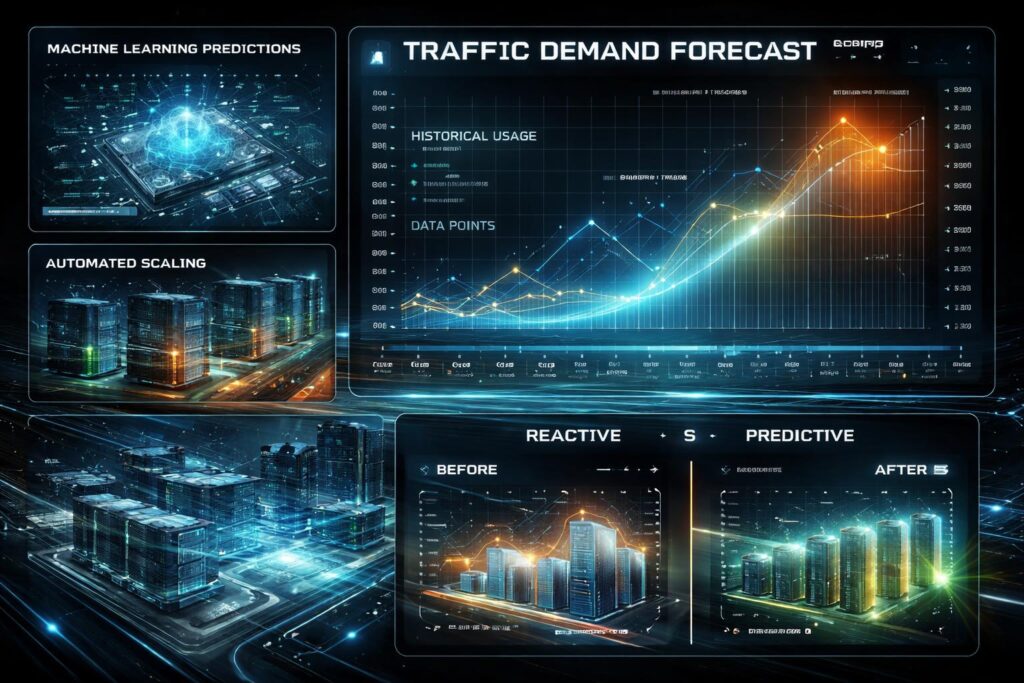
Predictive Autoscaling
Traditional autoscaling reacts to current conditions, adding capacity after load increases. This reactive approach creates brief periods of degraded performance during traffic surges. Predictive models analyze historical patterns to forecast future demand, scaling infrastructure proactively. Machine learning identifies daily cycles, weekly patterns, and seasonal trends that simple threshold-based rules miss.
These models consider multiple signals beyond basic CPU utilization. Request rates, queue depths, database connection pools, and business metrics all feed into predictions. The system learns that traffic spikes every Monday morning or that promotional campaigns trigger specific load patterns. This context allows more accurate capacity planning than reactive rules.
The financial benefit is substantial. Accurate predictions minimize over-provisioning while avoiding performance degradation. Infrastructure costs align more closely with actual demand rather than worst-case scenarios. Companies running cloud infrastructure at scale see meaningful cost reduction from optimized autoscaling.
Intelligent Performance Optimisation
AI-driven optimization adjusts system behavior in real-time based on current conditions. During high load, the system might reduce feature complexity by temporarily disabling non-essential functionality. Real-time analytics dashboards shift from per-second updates to per-minute updates. Image thumbnails decrease in quality. These adjustments maintain acceptable performance for critical features while gracefully degrading nice-to-have capabilities.
Smart routing directs requests to optimal backend instances based on predicted processing time. The system learns that certain query patterns execute faster on specific database replicas. Geographic routing algorithms consider both user location and current datacenter load to minimize latency while balancing capacity utilization.
Query optimization engines analyze database access patterns to suggest index improvements or schema modifications. They identify expensive queries consuming disproportionate resources and recommend rewrites or caching strategies. This continuous optimization reduces the manual effort required to maintain performance as data volumes grow.
AI-driven Incident Detection
Anomaly detection identifies unusual patterns that might indicate problems before customers are affected. Machine learning establishes baseline behavior for thousands of metrics simultaneously, something impossible for human operators. Deviations from these baselines trigger alerts when statistical confidence exceeds thresholds.
The research from IEEE on intelligent system monitoring demonstrates how these approaches reduce false positive alerts while catching subtle issues that traditional monitoring misses. The system learns that certain metric combinations predict outages minutes before they occur, providing time for automated remediation or human intervention.
Alert correlation connects related symptoms to identify root causes. When multiple services show degraded performance simultaneously, the system traces the issue to a shared dependency like a struggling database or network partition. This correlation reduces alert fatigue and accelerates incident response.
Integrating AI capabilities into SaaS platforms extends beyond infrastructure management. AI for SaaS Platforms: How to Enhance User Retention and Efficiency explores how intelligent features improve customer engagement and operational efficiency, making AI a core product differentiator rather than just an operational tool.
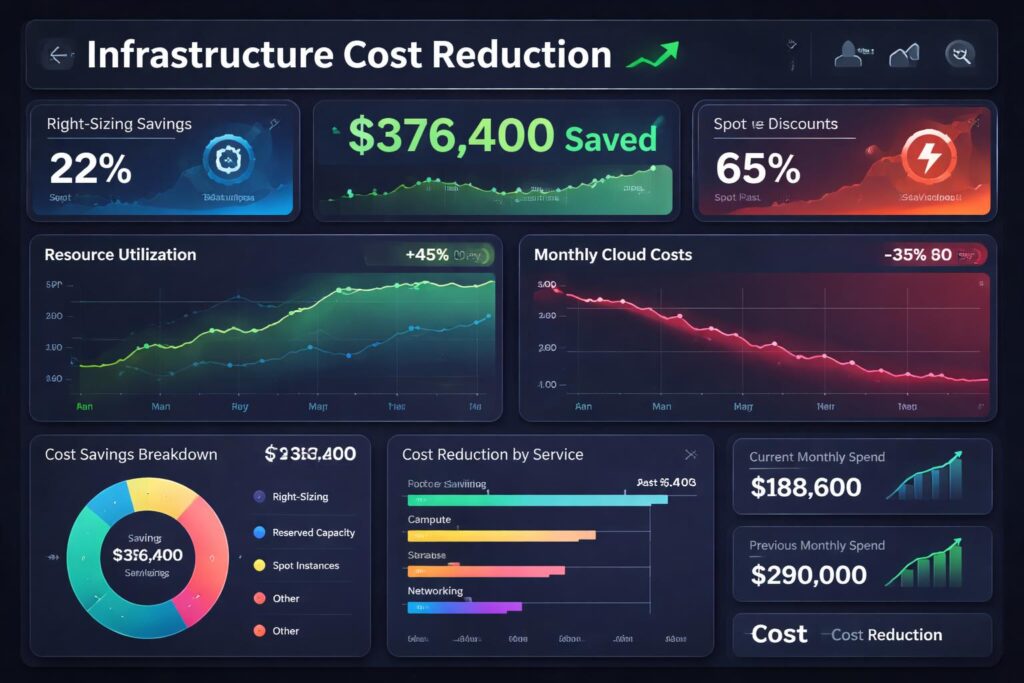
Cost-Effective Scaling Strategies for SaaS
Right-Sizing Infrastructure
Cloud providers offer dozens of instance types with different CPU, memory, and network characteristics. The default choice is rarely optimal. Systematic analysis of actual resource utilization reveals opportunities to select more appropriate instance types. CPU-intensive workloads benefit from compute-optimized instances. Memory-hungry applications need memory-optimized configurations.
Reserved capacity and committed use discounts provide substantial savings for predictable workloads. Companies commit to specific capacity levels for one to three years in exchange for discounted rates. Spot instances offer even deeper discounts for interruptible workloads like batch processing or development environments. The combination of purchase options reduces infrastructure costs by 40-60% compared to on-demand pricing.
Automatic shutdown of non-production environments during off-hours prevents waste. Development and staging systems that sit idle nights and weekends represent unnecessary expense. Simple scheduling scripts can stop these resources outside business hours, cutting costs proportionally to downtime with minimal engineering effort.
Identifying the Most Resource-Heavy Components
Not all system components consume resources equally. Analytics pipelines processing terabytes of data dwarf typical application servers in resource consumption. Identifying these heavy consumers focuses optimization efforts where they provide maximum return. Profiling tools track resource usage per service, revealing unexpected bottlenecks or inefficiencies.
Customer behavior varies widely. Enterprise customers with complex integrations generate more background processing than small businesses. Usage analytics segmented by customer tier inform capacity planning and help identify opportunities for more aggressive optimization in high-cost scenarios. Sometimes the answer is better algorithms; other times it involves customer education about expensive usage patterns.
Query optimization delivers disproportionate value. A single expensive database query executed thousands of times per hour can consume more resources than entire application servers. Database query analyzers identify slow queries and suggest improvements. Index additions, query rewrites, or result caching often provide order-of-magnitude performance improvements with minimal code changes.
Using Caching and Load Balancing to Reduce Load
Strategic caching reduces database load by orders of magnitude. Session data, user preferences, and reference data change infrequently yet are accessed constantly. Moving these to memory-based caches like Redis or Memcached eliminates database queries entirely for cache hits. Hit rates above 80% are common, translating directly to reduced database load and improved response times.
Content delivery networks cache static assets and API responses at edge locations near users. This geographical distribution reduces latency while offloading traffic from origin servers. For globally distributed applications, CDNs are essential infrastructure that improves performance while reducing bandwidth costs.
Load balancing distributes traffic across multiple application instances, but it also enables zero-downtime deployments. New code deploys to a subset of instances while the load balancer continues routing traffic to healthy servers. Once validated, the deployment proceeds to remaining instances. This pattern eliminates the maintenance windows and downtime associated with traditional deployment processes.
Challenges in Building Scalable Architectures
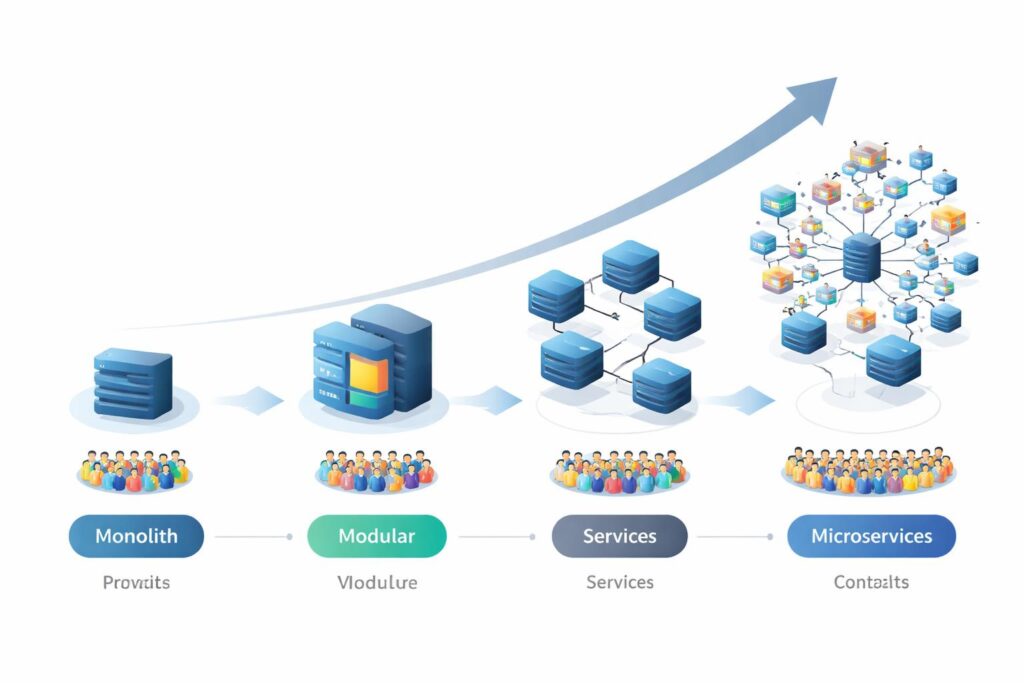
Over-Engineering and Premature Scaling
The temptation to architect for massive scale from day one leads to unnecessary complexity. A company with 100 customers does not need the same infrastructure as one serving 10 million. Premature optimization consumes engineering resources better spent on product development and customer acquisition. The goal is sufficient runway for near-term growth, not perfect architecture for theoretical future scale.
Microservices architectures impose operational overhead that small teams struggle to manage. Each service requires its own deployment pipeline, monitoring, and incident response procedures. Companies with limited engineering headcount benefit from starting with a well-structured monolith that can be decomposed later as team size and complexity warrant. The migration path matters more than the starting point.
Technical decisions have opportunity costs. Every hour spent on infrastructure is an hour not spent on features that attract customers. Finding the balance requires honest assessment of current needs versus future requirements. Some architectural decisions are reversible; others create long-term constraints. Distinguishing between them guides where to invest early versus where to defer.
Data Fragmentation
Microservices distribute data across multiple databases, creating challenges for operations that need consistent views across domains. Generating a unified customer report might require querying order, billing, and support databases. Joins across service boundaries are impossible, forcing application-level aggregation. This fragmentation increases complexity and creates eventual consistency scenarios where different services temporarily disagree about current state.
Data synchronization between services requires careful design. Event-driven patterns publish changes that interested services consume, but message ordering and delivery guarantees become critical. Lost events create data inconsistencies. Duplicate processing without idempotency causes corruption. Distributed transactions rarely work at scale, so systems must embrace eventual consistency and design for it explicitly.
Schema evolution becomes more complex with distributed data. Database changes must maintain compatibility with multiple service versions during rolling deployments. Backward-compatible changes deploy safely, but breaking changes require coordination across service teams. This coordination overhead slows iteration velocity unless teams establish clear contracts and versioning strategies upfront.
Security and Compliance at Scale
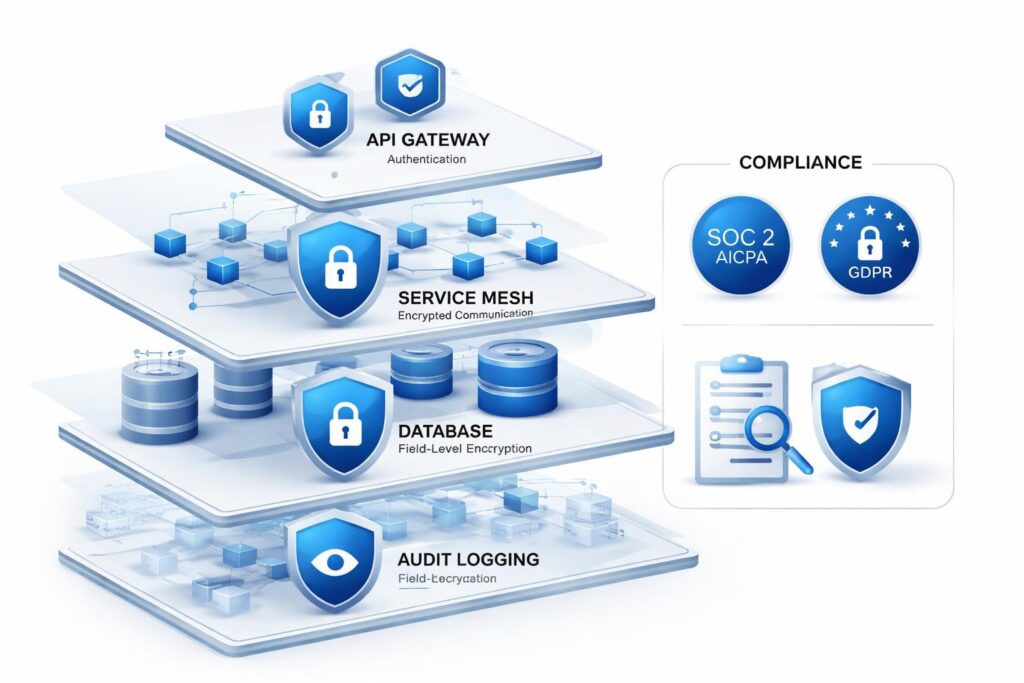
Distributed systems multiply the attack surface. Each service endpoint is a potential vulnerability. Service-to-service communication requires authentication and encryption, even within private networks. Managing certificates, keys, and access credentials across dozens of services introduces operational complexity and creates numerous opportunities for misconfiguration.
Access control becomes challenging when data flows through multiple services. Each service must validate that the requesting user has appropriate permissions for the requested operation. Passing user context through service chains while maintaining security requires consistent implementation of token validation and permission checking. Centralized authorization services help, but they introduce latency and become critical dependencies.
Audit logging must capture activity across all services to provide complete compliance trails. Correlating log entries from multiple services into coherent audit records requires consistent logging formats and distributed tracing infrastructure. Regulatory investigations might demand records spanning months or years, requiring long-term log retention with searchability and tamper-proof storage.
Financial institutions face particular challenges when implementing scalable architectures due to regulatory requirements. The Role of Managed IT Services in Modern Banking examines how specialized IT partners help banks navigate the intersection of scalability, security, and compliance in highly regulated environments.
Talent and Expertise Gap
Building and operating distributed systems requires specialized knowledge that many organizations lack. Cloud-native architecture, distributed systems patterns, and operational excellence disciplines represent distinct skill sets beyond traditional software development. The talent market for these capabilities is competitive, making hiring difficult and expensive.
Training existing teams addresses some of this gap, but real expertise comes from experience with production systems at scale. Companies without this institutional knowledge make predictable mistakes that more experienced teams avoid. Architecture decisions made early without proper expertise create technical debt that becomes expensive to remediate later.
External expertise through consulting engagements or technology partnerships provides faster access to proven practices. Partners with experience scaling similar systems bring patterns and approaches that accelerate development while avoiding common pitfalls. The investment in expert guidance pays for itself through faster time-to-market and more robust architecture.
Best Practices for Designing Scalable SaaS Architecture
Start With a Domain-Centric Architecture
Domain-driven design provides a framework for decomposing complex systems into manageable components. Identifying bounded contexts establishes clear boundaries where different teams can work independently. Each context represents a distinct business domain with its own data model, terminology, and rules. These boundaries align with organizational structure, enabling parallel development.
The goal is high cohesion within contexts and low coupling between them. Related functionality clusters within single services while unrelated capabilities separate into different services. This separation allows teams to understand their domain deeply without needing encyclopedic knowledge of the entire system. Changes within a context rarely affect other contexts, reducing coordination overhead.
Getting domain boundaries right requires business understanding as much as technical expertise. The architecture should reflect how the business thinks about its operations, not arbitrary technical divisions. Involving product managers and domain experts in architectural decisions ensures that service boundaries align with business reality.
Define Scalability Targets and Metrics
Specific, measurable goals guide architectural decisions better than vague aspirations. Defining target metrics like maximum latency, concurrent users, or transaction throughput creates objective criteria for evaluating design choices. These targets should be realistic based on customer requirements, not arbitrary numbers chosen because they sound impressive.
Key Performance Indicators for Scalable SaaS:
- Response time targets that align with user expectations and competitive benchmarks
- Concurrent user capacity that accommodates peak load plus growth margin
- Transaction throughput measured in requests per second across critical endpoints
- Data processing capacity for batch operations and analytics pipelines
- Error rate thresholds that define acceptable failure boundaries
- Resource utilization metrics that inform cost optimization efforts
Growth projections inform capacity planning. Understanding expected user growth, data volume increases, and feature complexity helps size infrastructure appropriately. Overbuilding wastes resources; underbuilding creates painful scaling crises. The right approach plans for 6-12 months of growth with clear upgrade paths for the next stage.
Regular performance testing validates that the system meets its targets. Load testing simulates expected traffic patterns to identify bottlenecks before they affect customers. Chaos engineering deliberately injects failures to ensure resilience mechanisms work as designed. These practices build confidence that the system will perform when customer load increases.
Prioritise Observability From Day One
Instrumentation cannot be retrofitted easily. Building observability into the system from the beginning establishes patterns that become natural parts of development. New features include metrics, logging, and tracing automatically because the infrastructure makes it straightforward and the culture expects it.
Distributed tracing deserves special attention because it reveals behavior in complex microservices architectures that logs and metrics cannot. Following a request through multiple service hops exposes performance bottlenecks, error propagation, and unexpected dependencies. Without tracing, debugging distributed systems becomes guesswork.
Error budgets create objective criteria for prioritizing reliability work. When error rates climb and the budget runs low, the message is clear that stability takes precedence over new features. This quantitative approach removes emotion from the stability-versus-velocity debate. The numbers show when it is time to slow down and fix underlying problems.
Work With an Experienced Tech Partner
Not every company needs to build deep cloud infrastructure expertise internally, especially in early growth stages. Technology partners with proven experience scaling SaaS applications provide faster paths to production-ready architecture. The key is selecting partners with relevant domain experience, not just general cloud competency.
Critical Evaluation Criteria:
- Demonstrated experience scaling applications in your industry vertical
- Technical depth across cloud platforms, container orchestration, and observability tools
- DevOps maturity including CI/CD practices and infrastructure-as-code capabilities
- Security expertise covering both application and infrastructure layers
- Cultural alignment with your organization’s values and working style
- Knowledge transfer commitment to build internal capabilities rather than create dependency
Evaluation criteria should include demonstrated scaling experience, expertise with the specific technology stack, maturity in DevOps practices, and cultural fit with the organization. References from companies at similar growth stages provide insight into what working with the partner actually involves. The relationship works best as a collaboration that builds internal capability rather than creating dependency.
The partner should transfer knowledge through pairing and documentation, not work in isolation. The goal is to build internal capacity to operate and evolve the system independently. Partners who hoard knowledge create future problems. Those who actively develop client team capabilities provide lasting value beyond the engagement itself.
Comparing Architectural Approaches for Different Growth Stages
| Growth Stage | User Range | Recommended Architecture | Key Priorities | Infrastructure Investment |
|---|---|---|---|---|
| Early Stage | 0-10K users | Modular monolith with clear domain separation | Feature velocity, market fit validation | Minimal cloud resources, managed databases |
| Growth Stage | 10K-100K users | Hybrid architecture with extracted high-load services | Performance optimization, reliability improvements | Auto-scaling groups, caching layer, monitoring |
| Scale Stage | 100K-1M users | Full microservices with event-driven patterns | Horizontal scalability, global distribution | Multi-region deployment, dedicated teams per service |
| Enterprise Stage | 1M+ users | Distributed platform with specialized data stores | Cost optimization, advanced observability | Complex infrastructure with custom tooling |
Technology Stack Considerations by Component
| Component | Small Scale Options | Enterprise Scale Options | Key Trade-offs |
|---|---|---|---|
| Application Layer | Monolithic frameworks (Rails, Django) | Microservices (Spring Boot, Node.js clusters) | Development speed vs operational complexity |
| Database | Single managed database (RDS, Cloud SQL) | Distributed databases (Aurora, Spanner, Cassandra) | Consistency vs availability and partition tolerance |
| Caching | In-memory caching (built-in) | Distributed cache clusters (Redis, Memcached) | Simplicity vs cache hit rates and invalidation control |
| Message Queue | Simple queue services (SQS, Pub/Sub) | Enterprise messaging (Kafka, RabbitMQ) | Ease of use vs message ordering and delivery guarantees |
| Search | Database full-text search | Specialized search engines (Elasticsearch, Algolia) | Resource efficiency vs query performance and relevance |
| Monitoring | Basic cloud monitoring | Full observability stack (Prometheus, Grafana, Jaeger) | Cost vs debugging capability and operational insight |
Real-World Case Examples of Scaling SaaS Systems
A global customer relationship management platform experienced explosive growth that pushed their monolithic architecture beyond sustainability. Database locks caused request timeouts during peak usage. New feature development slowed as teams feared breaking existing functionality. The system had reached the point where incremental improvements would not solve fundamental architectural limitations.
The company embarked on a phased migration to microservices, starting with the most problematic components. The authentication system separated first, then billing, then the analytics pipeline. Each extraction reduced load on the monolith while establishing patterns for future migrations. Service boundaries followed business domains rather than technical layers, ensuring each service had clear ownership and purpose.
After 18 months, the platform operated as 23 distinct services handling 10x the original transaction volume. Response times dropped by 60% despite the increased load. Development velocity increased as teams deployed their services independently, no longer waiting for coordinated releases. The migration required significant investment but prevented the customer churn and reputational damage that system instability would have caused.
A fintech payment processing company faced strict latency requirements due to the real-time nature of financial transactions. Customers expected sub-100-millisecond response times for transaction authorization, which became impossible as transaction volume grew. Traditional database scaling approaches could not meet these requirements without prohibitive costs.
The solution involved a sophisticated caching architecture with write-through and write-behind patterns depending on data criticality. Hot data like account balances and fraud detection models stayed in distributed memory caches. Database writes happened asynchronously without blocking transaction processing. Regional deployments positioned compute resources near customers, reducing network latency.
The architectural changes reduced p95 latency from 400 milliseconds to 60 milliseconds while supporting 5x transaction volume growth. Infrastructure costs grew linearly with volume rather than exponentially as they had before the redesign. The company met its SLA commitments consistently, enabling expansion into new markets with stringent performance requirements. Financial services companies facing similar challenges can explore How Open Banking API Integration Is Reshaping Customer Experience for insights on modern integration patterns that support scalable architectures.
An analytics platform processing billions of events daily struggled with query performance as customer datasets grew. Interactive dashboards took minutes to refresh, frustrating users and driving them to competitive products. The existing data warehouse architecture could not parallelize queries effectively, creating a fundamental scalability barrier.
The company migrated to a data lake architecture with specialized query engines for different access patterns. Batch processing pipelines transformed raw event data into optimized formats for analytical queries. Columnar storage and aggressive partitioning reduced scan volumes dramatically. Pre-aggregation generated summary tables for common query patterns, trading storage for query performance.
Query response times improved from minutes to seconds for typical dashboard operations. The system scaled to handle 10x data volume growth over two years without performance degradation. Engineering teams could focus on advanced analytics features rather than constant performance firefighting. The investment in proper data architecture unlocked product capabilities that directly drove customer acquisition.
Industry-Specific Considerations
Financial services organizations operate under unique constraints that affect architectural decisions. Regulatory compliance, data sovereignty requirements, and security standards shape every technical choice. Top 5 Trends in FinTech App Development for 2026 explores how fintech companies balance innovation with regulatory requirements while building scalable platforms.
Banking institutions particularly benefit from systematic approaches to infrastructure modernization. Legacy systems must coexist with modern architectures during extended transition periods. Why Financial Institutions Are Investing in AI Integration Services examines how banks implement AI capabilities within existing architectural constraints while preparing for future scale.
The broader shift from monolithic legacy systems to intelligent, scalable architectures represents a fundamental transformation. From Legacy to Intelligence: The Rise of AI Software Development Companies discusses how specialized development partners help organizations navigate this transition while maintaining operational continuity.
Financial software development requires particular attention to security and compliance. Why Use AI in Financial Software Development explores how AI capabilities integrate into financial platforms while meeting regulatory standards and scaling requirements that define this sector.
Conclusion
Scalable SaaS architecture represents both technical challenge and strategic necessity for high-growth companies. The architectural foundation determines whether a company can execute on its market opportunity or falters under operational burden. Cloud-native approaches, distributed systems patterns, and systematic engineering practices provide the capabilities needed to serve growing customer bases without constant crisis management.
The path forward requires balancing immediate needs against future requirements, avoiding both premature optimization and technical debt that constrains growth. Success comes from understanding architectural principles deeply while maintaining pragmatism about implementation timing. Companies that invest in scalable architecture early position themselves to capture market opportunities that competitors cannot service. Those that delay face painful migration projects under pressure from customers experiencing degraded service. The choice is between proactive architectural evolution and reactive crisis management.
Ready to build infrastructure that scales with your ambitions? Our team brings proven experience designing and implementing scalable SaaS architectures for high-growth companies. We help technical leaders navigate the complexity of cloud-native transformation, from initial architecture design through production deployment and ongoing optimization. Contact us to discuss how we can accelerate your scaling journey while avoiding common pitfalls that slow competitors down.







